S3バケットの中身をCLIで空にする方法
S3バケットを削除しようとした際、バケット内に何らかのデータが入っていると以下のようなエラーが出て削除できません。
BucketNotEmpty: The bucket you tried to delete is not empty status code: 409,
AWSコンソールから手動でバケットを空にしていってもいいのですが、少し手間なのでCLIから実行します。
以下のコマンドを実行すると、確認なしの問答無用で削除処理が始まるので用法には十分注意しましょう。
aws s3 rm s3://<bucket-name> --recursive
References
【JavaScript】条件を満たす場合のみオブジェクトにプロパティを追加する
忘れがちでよく検索するのでメモ。
const a = { ...(someCondition && { b: 5 }), };
References
【WSL2】通信が遅い、安定しない
症状
curl, wget, npm installなどのコマンドの動作がやたら遅く、 npx でのコマンド実行に至ってはほぼ動作しない状態になっていた。
環境
- Windows 11
- Ubuntu 20.04.2
解決策
こちらによると、WSL2のUbuntuで設定されているnameserverを修正すれば直るらしい。
sudo rm /etc/resolv.conf sudo bash -c 'echo "nameserver 1.1.1.1" > /etc/resolv.conf' # 代替DNSも設定したほうが良いと思うので sudo bash -c 'echo "nameserver 1.0.0.1" >> /etc/resolv.conf' sudo bash -c 'echo "[network]" > /etc/wsl.conf' sudo bash -c 'echo "generateResolvConf = false" >> /etc/wsl.conf' # 削除保護 sudo chattr +i /etc/resolv.conf
以下は修正前後でのSpeedtest-cliの結果
Before

After

おそらく名前解決に失敗していたせいで通信が上手くいっていなかったと思われる。
ちなみに、最後に設定した削除保護を解除したい場合は以下コマンドで可能。
sudo chattr -i /etc/resolv.conf
References
【aws】FirehoseのDynamic Partitioningを試す
Amazon Kinesis Data Firehoseに、ついにDynamic Partitioningが実装されました!
Introducing Dynamic Partitioning in Amazon Kinesis Data Firehose
というわけで早速試していこうと思います。
FirehoseにおけるS3転送時の問題点
今回実装されたDynamic Partitioningの話に入る前に、そもそもFirehoseを利用する上で困っていた仕様を簡単におさらいします。
FirehoseではStreamに溜まったデータをS3に転送する際、Firehoseが処理を行った時間で自動的にディレクトリ構造を構成し、その配下にファイルを出力していました。
この仕様だと、S3に保存したデータをAthena等で分析する際、実際のデータ(各レコード内のタイムスタンプなど)と、S3上のディレクトリ構造であるパーティションに差異が生まれるため、それを考慮したクエリを発行するか、別途パーティション内のデータを整頓する処理が必要になっていました。
また、何らかのIDなど、時間以外でのパーティション構成を採ることができない点も問題でした。
そもそもこの仕様があるため、StreamにFirehoseを使わないアーキテクチャを採用するケースもあったように思います。
それが今回のDynamic Partitioningの導入により、FirehoseのStreamに流入したレコードの、任意のデータをパーティションのキーとして設定できるようになりました。
これにより、従来であれば別途パーティションのために行っていた整頓処理などが、Firehose単体で完結できるようになります。
Dynamic Partitioning
パーティションキー設定の方法
現在のところDynamic Partitioningでパーティションキーを指定する方法として、2つの方法が提供されているようです。
1 inline parse
jq を使用してレコードからパーティションキーを抽出します
2 AWS Lambda
既存のデータ変換Lambdaの仕組みを流用します
簡易な要件はinline parseでおおむね対応できそうです。
パーティションキーに複雑な要件が必要であったり、既にデータ変換Lambdaを利用している場合、またinline parseの処理による料金計算(詳細は後述)を嫌う場合などは、Lambdaを用いてパーティションキーを設定する方法が良さそうです。
ではそれぞれのパーティションキー設定を順に試してみます。
手順
今回は以下のデータ構造のサンプルデータを用います(Dynamic Partitioningの公式DocやFirehoseの作成画面で提示されているもの)。
個人的に日時データはISO8601の形式で扱うことが多いので、そのサンプルデータを末尾に付与した版です。
{ "type": { "device": "mobile", "event": "user_clicked_submit_button" }, "customer_id": "1234567890", "event_timestamp": 1565382027, "region": "pdx", "createdAt": "2021-09-01T13:24:10Z" }
(キー名に統一感がなくちぐはぐですがご容赦ください😫)
構成はIoT Coreを用いた以下の構成とします。

S3バケット作成
まず任意の名前でバケットを用意します。
以下、作成手順で特に言及のない部分はデフォルト値を使用します。
Name: firehose-dynamic-partition
Firehose作成
次にFirehoseを作成していきます。
Kinesisのコンソールを開き > 配信ストリームを作成
- Source:
Direct PUT - Destination:
S3 - Delivery stream name: (任意)
- S3 bucket:
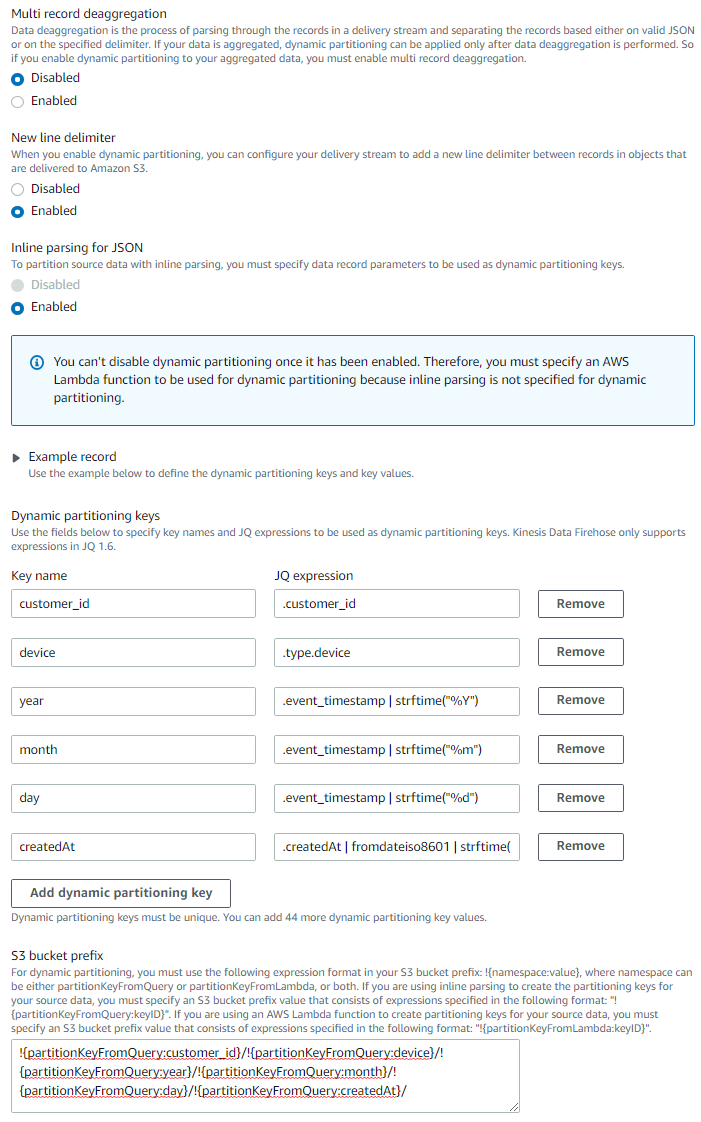
firehose-dynamic-partition(先ほど作成したS3バケット) - Dynamic partitioning:
Enabled- New line delimiter:
Enabled - Inline parsing for JSON:
Enabled - Dynamic partitioning keys を以下の画像のように設定します。
createdAtの省略されている部分は.createdAt | fromdateiso8601 | strftime("%Y-%m-%d %H:%M:%S")です
- 入力後、
Add dynamic partitioning keyボタンを押すと、S3 bucket prefixの欄に設定したパーティションキーの設定が出力されます。- S3 bucket prefix:
!{partitionKeyFromQuery:customer_id}/!{partitionKeyFromQuery:device}/!{partitionKeyFromQuery:year}/!{partitionKeyFromQuery:month}/!{partitionKeyFromQuery:day}/!{partitionKeyFromQuery:createdAt}/
- S3 bucket prefix:
- New line delimiter:
- Buffer interval:
60
※作成画面の公式の jq の例だと strftime はシングルクォーテーションで表記されていましたが、実行時jqのパースエラーになったためダブルクォーテーションにしています。
※createdAt のパーティションに特に意味はありません。ISO8601形式の例示目的です。
IoT Core rule作成
IoT Coreのコンソールを開き > ACT > ルール > 作成
- Name:
firehose_dynamic_partition(任意) - ルールクエリステートメント:
SELECT * FROM 'iot/firehose' - アクションの追加
- Amazon Kinesis Firehose ストリームにメッセージを送信する
- ストリーム名: (先ほど作成したFirehose stream)
- Separator: 区切り文字なし
- ロールの作成:任意の名前をつける
- アクションの追加
- Amazon Kinesis Firehose ストリームにメッセージを送信する
- ルールの作成
動作確認
以上の作業でinline parseの構成はできたので、動作確認をしていきます。
IoT Core > テスト > MQTTテストクライアント
を押下し、テストクライアントページを開き、【トピックに公開する】タブを選択する。
トピック名: iot/firehost
下記のメッセージペイロードを入力し、発行ボタンを押します。
{ "type": { "device": "mobile", "event": "user_clicked_submit_button" }, "customer_id": "1234567890", "event_timestamp": 1565382027, "region": "pdx", "createdAt": "2021-09-01T13:24:10Z" }
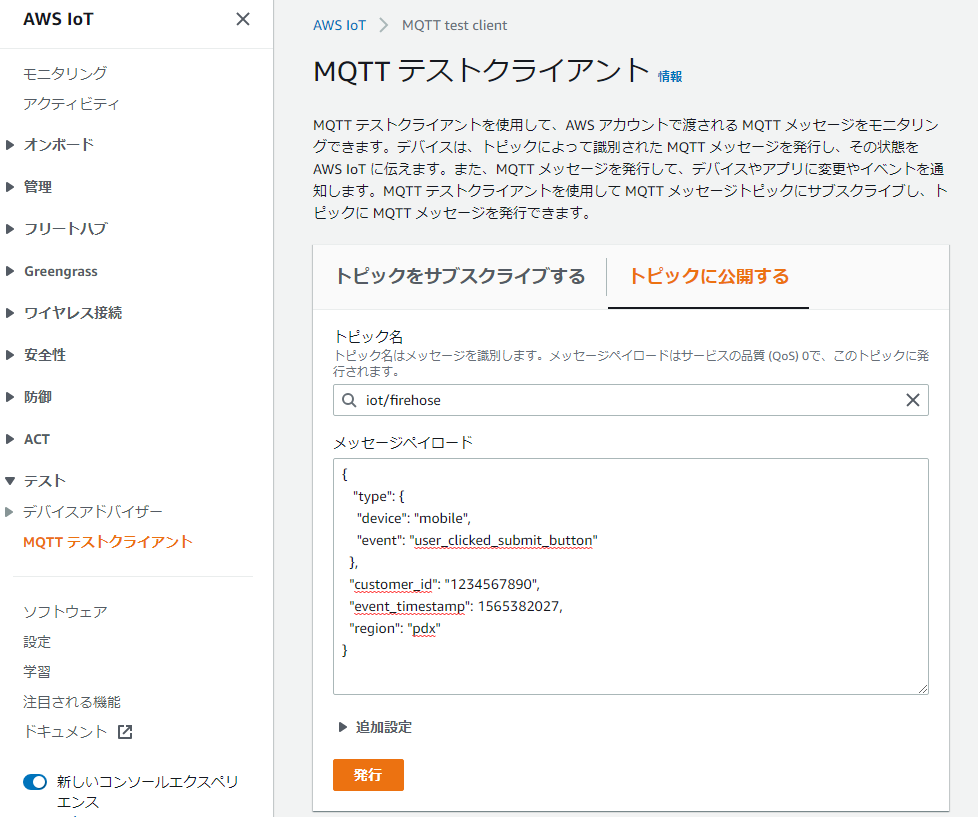
試しに何度か発行します。
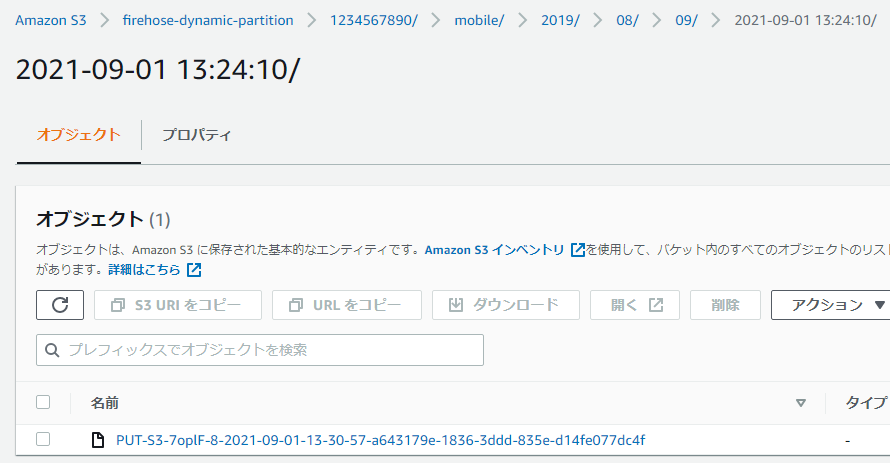
FirehoseのInterval設定を60秒にしたので、約1分後にS3内に指定したパーティション(ディレクトリ構造)でファイルが出力されていることが確認できます。
Lambda版の動的パーティション
続いて、Lambdaでのパーティションキー設定を試していきます。
先程作成したFirehoseを編集します。
Firehose > 作成したStream > Configuration > Transform and convert records > Edit
- Data transformation:
Enabled- Create function
- General Kinesis Data Firehose Processing
- 関数名:
firehose-dynamic-partition-lambda(任意) - 基本的な Lambda アクセス権限で新しいロールを作成 を選択して関数の作成
- Create function
Lambda Functionが作成されたら、以下のコードを貼り付けてデプロイします。
console.log('Loading function'); exports.handler = async (event, context) => { /* 各レコードにpartitionKeysのmetadataを設定する */ const records = event.records.map((record) => { const payload = JSON.parse( Buffer.from(record.data, 'base64').toString('utf-8') ); console.log('Decoded payload:', payload); const d = new Date(payload.event_timestamp * 1000); // epoch time(sec)をmsでinitialize const partitionKeys = { customer_id: payload.customer_id, device: payload.type.device, year: d.getUTCFullYear(), month: ('00' + (d.getUTCMonth() + 1)).slice(-2), // getUTCMonthは0-11を返すため day: ('00' + d.getUTCDate()).slice(-2), createdAt: payload.createdAt.replace('T', ' ').replace('Z', ''), // 2021-09-01T13:24:10Z -> 2021-09-01 13:24:10 }; return { recordId: record.recordId, data: record.data, result: 'Ok', metadata: { partitionKeys }, }; }); console.log(`Processing completed. Successful records ${records.length}.`); return { records }; };
パーティションキーの設定がinline parseと同様になるように多少処理を実装していますが、基本的には、StreamのEventとして渡ってきた records に対して、 metadata として partitionKeys の値を追記した records を作成し、returnしてあげることでLambdaでのパーティションキー設定は完了です。
Firehoseの編集画面に戻り、Browseから先程作成したLambdaを選択します。
その他の設定はデフォルトのまま Save changesを押下します。
Lambdaの変換処理でpartitionKeyを設定するようにしたため、jqを使用したinline parseの設定をオフにします。
Firehose > 作成したStream > Configuration > Destination settings > Edit
Inline parsing for JSON: Disabled
※Dynamic Partitioningを有効にした場合、データ変換用のLambdaを設定していないと、以下のようにinline parseを無効化することができません。

S3 bucket prefixを以下のように、Lambdaで設定したPartition Keyを使用するように修正します。
!{partitionKeyFromLambda:customer_id}/!{partitionKeyFromLambda:device}/!{partitionKeyFromLambda:year}/!{partitionKeyFromLambda:month}/!{partitionKeyFromLambda:day}/!{partitionKeyFromLambda:createdAt}/
修正後、Save changesを押下します。
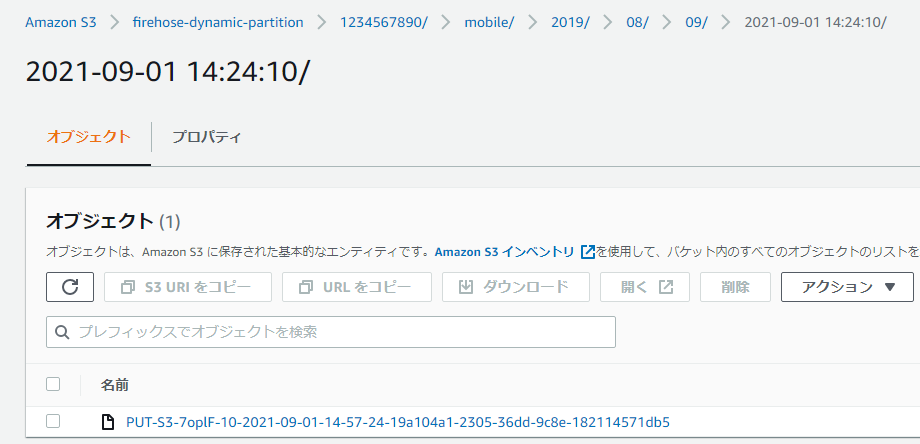
動作確認で実施した手順と同様に、以下のメッセージペイロードをIoT Coreのテストクライアントから送信し、処理が実行されるまでの時間待機します。
(createdAt の値のみ最初のデータの1時間後にしています)
{ "type": { "device": "mobile", "event": "user_clicked_submit_button" }, "customer_id": "1234567890", "event_timestamp": 1565382027, "region": "pdx", "createdAt": "2021-09-01T14:24:10Z" }
無事指定したパーティションにファイルが出力されました!
料金
Dynamic Partitioningの利用には追加の料金がかかるため注意が必要です。
詳細は末尾の公式pricingを参考にして頂くとして、主に以下3つの合計が料金になります。

公式の試算結果を参照するに、あまり大きな額ではないかと思いますが、利用方法によって価格が変わってきますので、自身のユースケースで試算してみるのがよいかと思います。
パーティションキー設定のために別途利用していた料金と比べて、高額になることはあまりないのかなと思いました。
アーキテクチャもシンプルになるし一石二鳥ですね。
注意点
以下目についた注意事項です。
詳しくは公式Docをご参照ください。
- 動的パーティションを有効化できるのは新規のFirehose streamのみ
- 動的パーティションで作成していれば、後からパーティションキーを変更することは可能
- 動的パーティションで作成したFirehose streamの動的パーティションを無効化することもできない
- 同時に処理可能なパーティションの最大は500件
- それを超えたパーティションキーのデータはエラー行き
所感
IoT Analyticsでは今回Firehoseに追加されたDynamic Partitioningに似たことができていたため、Firehoseでは何故できないのだ……と頭を抱えていたのですが、無事機能がリリースされてとても嬉しいです。
ここ2週間くらいFirehose + S3 + Athenaの構成で悩んでいたため、リリースページを見たときは興奮のあまり失神しそうになりましたが、よく考えると最初から用意しておいてよという気持ちも……。
不良が良いことすると、とてもよく見える理論ですかね。
ともかく、今後Firehoseを用いた構成がシンプルかつ利用しやすくなるのでとても良かったです!
Refs
NestJS + MySQL + Prisma + GraphQL環境の構築
タイトルの組み合わせで、GraphQLのデータ取得Queryが実行可能なところまで構築する。
なお、GraphQLの実装はコードファーストとスキーマファーストの2種類があるが、今回はコードファーストで実装する。
※Prismaはライブラリの更新速度が早く、コマンドが陳腐化している可能性があるため注意
コマンド実行後のエラー等に最新verでの実行方法の補足が表示されるため、エラーが出た場合はそちらを参考にする
環境
- NestJS 7系
Init Nest
パッケージ追加とプロジェクトの初期化を行う。
npm i -g @nestjs/cli
nest new app-name
Init MySQL
MySQLを起動するdocker-compose.ymlを用意する。
※開発用途で脆弱な設定であるため注意。
version: '3.8' services: db: image: mysql:8 container_name: db environment: MYSQL_ROOT_PASSWORD: password ports: - '3306:3306' command: --default-authentication-plugin=mysql_native_password volumes: - ./mysql:/var/lib/mysql
MySQLを起動する。
docker-compose up
Init Prisma
Prismaを設定する。
yarn add --dev prisma
npx prisma init
生成されたschema.prismaのproviderをMySQLに変更。
- provider = "postgresql" + provider = "mysql"
また、データベースの初期化用にIDだけのユーザーモデルを追記する。
model User {
id String @id @default(uuid())
}
.envに接続情報を定義
# Database DATABASE_URL="mysql://root:password@localhost/db"
マイグレーションを実行する。
npx prisma migrate dev
nestjsでPrismaのServiceを用意する。
nest g module prisma nest g service prisma
作成したprisma.service.tsを下記のように修正。
import { Injectable, OnModuleInit, OnModuleDestroy } from '@nestjs/common'; import { PrismaClient } from '@prisma/client'; @Injectable() export class PrismaService extends PrismaClient implements OnModuleInit, OnModuleDestroy { async onModuleInit() { await this.$connect(); } async onModuleDestroy() { await this.$disconnect(); } }
prisma.module.tsでPrismaServiceをエクスポートする。
import { Module } from '@nestjs/common'; import { PrismaService } from './prisma.service'; @Module({ providers: [PrismaService], exports: [PrismaService], }) export class PrismaModule {}
GraphQL設定
必要なライブラリをインストールする。
yarn add @nestjs/graphql graphql-tools graphql apollo-server-express
app.module.tsにGraphQLModuleのインポート設定を追記。
import { Module } from '@nestjs/common'; import { GraphQLModule } from '@nestjs/graphql'; import { Request, Response } from 'express'; import { join } from 'path'; import { AppController } from './app.controller'; import { AppService } from './app.service'; import { PrismaModule } from './prisma/prisma.module'; @Module({ imports: [ GraphQLModule.forRoot({ autoSchemaFile: join(process.cwd(), 'src/schema.gql'), // Resolverでexpressのreq/resを利用する場合設定する // context: ({ req, res }): { req: Request; res: Response } => ({ // req, // res, // }), // corsの設定が必要な場合 // cors: { // origin: process.env.ORIGINS?.split(','), // credentials: true, // }, debug: process.env.NODE_ENV === 'production' ? false : true, playground: process.env.NODE_ENV === 'production' ? false : true, }), PrismaModule, ], controllers: [AppController], providers: [AppService], }) export class AppModule {}
コードファーストの定義を簡略化するため、nest-cli.jsonに下記設定を追記。
{ "collection": "@nestjs/schematics", "sourceRoot": "src", "compilerOptions": { "plugins": [ { "name": "@nestjs/graphql/plugin", "options": { "typeFileNameSuffix": [ ".input.ts", ".args.ts", ".entity.ts", ".model.ts" ] } } ] } }
GraphQL実装
Userモデルのデータを取得できるリゾルバを作成する。
nest g mo Users nest g resolver Users nest g service Users
users.module.tsのimportsにPrismaModuleを追記。
+ imports: [PrismaModule]
entityを定義する。
touch src/users/user.entity.ts
import { ObjectType } from '@nestjs/graphql'; @ObjectType() export class User { id!: string; }
users.service.tsにPrismaを使用してユーザーを全件取得するメソッドを定義する。
import { Injectable } from '@nestjs/common'; import { PrismaService } from 'src/prisma/prisma.service'; @Injectable() export class UsersService { constructor(private readonly prisma: PrismaService) {} findAll() { return this.prisma.user.findMany(); } }
users.resolver.tsにユーザーを全件取得するリゾルバを定義する。
import { Query, Resolver } from '@nestjs/graphql'; import { User } from './user.entity'; import { UsersService } from './users.service'; @Resolver() export class UsersResolver { constructor(private readonly usersService: UsersService) {} @Query(() => [User], { name: 'users' }) findAll(): Promise<User[]> { return this.usersService.findAll(); } }
app.module.ts にUsersModule のimportを追加する。
... imports: [ ... UsersModule, ], ...
Prisma Studioを用いて、Webインターフェースから適当にUserを追加する。
npx prisma studio
# デフォルトでhttp://localhost:5555でPrisma Studioが起動するので、ユーザーテーブル選択後、Add recordからデータを追加する
接続確認
実際にアプリケーションを起動し、GraphQL Playgroundからユーザーデータを取得する。
yarn start:dev
アプリケーションが起動したらhttp://localhost:3000/graphqlにアクセスし、下記クエリを実行する。
query { users { id } }
データが正常に取得できればセットアップ完了。
{ "data": { "users": [ { "id": "4d3147b8-0b2d-4c6b-a54d-b9bbb2d627b5" }, { "id": "590ee871-e7ba-42d0-be0c-ce55377112cf" }, { "id": "9177215b-b055-4140-84bf-e89233d1ef49" } ] } }
References
【Chart.js】図のタイトルを複数行にする
環境
- Chart.js 2.9.4
方法
Chartのoptionsのtitleに配列でStringを渡す。
window.onload = function() { // 積み上げ棒と折れ線 var ctx = document.getElementById('canvas').getContext('2d'); var myChart = new Chart(ctx, { type: 'pie', data: { datasets: [{ data: [ Math.floor(Math.random() * Math.floor(100)), Math.floor(Math.random() * Math.floor(100)), Math.floor(Math.random() * Math.floor(100)), ], backgroundColor: [ 'rgb(255, 0, 0)', 'rgb(0, 255, 0)', 'rgb(0, 0, 255)', ], label: 'Dataset pie' }], labels: [ 'Red', 'Green', 'Blue', ] }, options: { title: { display: true, text: ['Title Line', 'New Line!'] // HERE! } } }); }
参考
【Chart.js】積み上げ棒グラフと折れ線グラフを同じ図上に表示する
環境
- Chart.js 2.9.4
方法
データセット内のyAxisIDを指定し、ChartのoptionsでyAxesを用意することで実現できる。
例
var barChartData = { labels: ['January', 'February', 'March'], datasets: [ { type: 'line', label: 'Dataset line', backgroundColor: 'rgb(255, 255, 255)', borderColor: 'rgb(255, 255, 255)', borderWidth: 2, fill: false, data: [ Math.floor(Math.random() * Math.floor(300)), Math.floor(Math.random() * Math.floor(300)), Math.floor(Math.random() * Math.floor(300)), ] }, { type: 'bar', label: 'Dataset stacked bar 1', backgroundColor: 'rgb(255, 99, 132)', yAxisID: "bar-stacked", // HERE! data: [ Math.floor(Math.random() * Math.floor(100)), Math.floor(Math.random() * Math.floor(100)), Math.floor(Math.random() * Math.floor(100)), ], }, { type: 'bar', label: 'Dataset stacked bar 2', backgroundColor: 'rgb(75, 192, 192)', yAxisID: "bar-stacked", // HERE! data: [ Math.floor(Math.random() * Math.floor(100)), Math.floor(Math.random() * Math.floor(100)), Math.floor(Math.random() * Math.floor(100)), ] } ] }; window.onload = function() { var ctx = document.getElementById('canvas'); var myChart = new Chart(ctx, { type: 'bar', data: barChartData, options: { title: { display: true, text: 'Chart.js Stacked Bar and Line Chart' }, scales: { xAxes: [{ stacked: true, }], // 折れ線用と積み上げ棒用のY軸を用意する yAxes: [{ stacked: false }, { id: "bar-stacked", stacked: true, position: 'right', }] }, } }); }
参考
CentOS6のコンテナでVSCodeのRemote Containersを使うために
下記の公式Docに記載の通り、必要なパッケージをコンテナにインストールする。
Remote Development with Linux#Updating glibc and libstdc++ on RHEL / CentOS 6
なお、CentOS6のサポートは2020-11-30で既に切れているため使わないようにしよう。
Dockerfileの例
FROM centos:6 RUN yum -y install wget tar # Update glibc RUN wget -q http://copr-be.cloud.fedoraproject.org/results/mosquito/myrepo-el6/epel-6-x86_64/glibc-2.17-55.fc20/glibc-2.17-55.el6.x86_64.rpm \ && wget -q http://copr-be.cloud.fedoraproject.org/results/mosquito/myrepo-el6/epel-6-x86_64/glibc-2.17-55.fc20/glibc-common-2.17-55.el6.x86_64.rpm \ && wget -q http://copr-be.cloud.fedoraproject.org/results/mosquito/myrepo-el6/epel-6-x86_64/glibc-2.17-55.fc20/glibc-devel-2.17-55.el6.x86_64.rpm \ && wget -q http://copr-be.cloud.fedoraproject.org/results/mosquito/myrepo-el6/epel-6-x86_64/glibc-2.17-55.fc20/glibc-headers-2.17-55.el6.x86_64.rpm \ && wget -q https://copr-be.cloud.fedoraproject.org/results/mosquito/myrepo-el6/epel-6-x86_64/glibc-2.17-55.fc20/glibc-utils-2.17-55.el6.x86_64.rpm \ && wget -q https://copr-be.cloud.fedoraproject.org/results/mosquito/myrepo-el6/epel-6-x86_64/glibc-2.17-55.fc20/glibc-static-2.17-55.el6.x86_64.rpm \ && rpm -Uh --force --nodeps \ glibc-2.17-55.el6.x86_64.rpm \ glibc-common-2.17-55.el6.x86_64.rpm \ glibc-devel-2.17-55.el6.x86_64.rpm \ glibc-headers-2.17-55.el6.x86_64.rpm \ glibc-static-2.17-55.el6.x86_64.rpm \ glibc-utils-2.17-55.el6.x86_64.rpm \ && rm *.rpm # Update libstdc++ RUN wget -q https://copr-be.cloud.fedoraproject.org/results/mosquito/myrepo-el6/epel-6-x86_64/gcc-4.8.2-16.3.fc20/libstdc++-4.8.2-16.3.el6.x86_64.rpm \ && wget -q https://copr-be.cloud.fedoraproject.org/results/mosquito/myrepo-el6/epel-6-x86_64/gcc-4.8.2-16.3.fc20/libstdc++-devel-4.8.2-16.3.el6.x86_64.rpm \ && wget -q https://copr-be.cloud.fedoraproject.org/results/mosquito/myrepo-el6/epel-6-x86_64/gcc-4.8.2-16.3.fc20/libstdc++-static-4.8.2-16.3.el6.x86_64.rpm \ && rpm -Uh \ libstdc++-4.8.2-16.3.el6.x86_64.rpm \ libstdc++-devel-4.8.2-16.3.el6.x86_64.rpm \ libstdc++-static-4.8.2-16.3.el6.x86_64.rpm \ && rm *.rpm
EOSLはきちんと意識しよう。
起動しなくなったBOSE NOISE CANCELLING HEADPHONES 700(Bose NC 700)を蘇らせる
2019年10月に購入してから約8ヵ月程愛用していたBose NC 700が、1週間程前から起動しなくなってしまったため、対処方法を探して解決した。

BOSE NOISE CANCELLING HEADPHONES 700 ワイヤレスノイズキャンセリングヘッドホン Amazon Alexa搭載 トリプルブラック
- 発売日: 2019/09/12
- メディア: エレクトロニクス
今のところ対処方法の日本語情報が見当たらなかったので、メモとして記録しておく。
注意事項 / 免責事項
当記事内で紹介する対処方法を実行すると、メーカーの保証対象外となり、また機器が完全に故障する場合があります。
記事内の情報で発生した損害について当方では一切責任を負いません。全て自己責任で実施するようお願いします。
不安な方はメーカーサポートから正規のルートで問い合わせをしましょう。
結論
- 今回の問題はファームウェア1.4.12に内包されていると思われるバグに起因している可能性が高い
- 非公式手順に基づくファームウェアダウングレードを行うことで、再度ヘッドホンが起動するようになった
症状
- ヘッドホンを通常利用している最中、突如電源が切れる
- 以後、電源をONにしても起動音が鳴っている最中に電源が切れる
- USB-Cケーブル横のLEDインジケータ赤白に点滅する
対処方法
Redditのスレで紹介されている手順に沿ってファームウェアダウングレードの手順を実施する。
私の環境はWindowsなので、macOSでは動作確認していないが、手順は記載しておく。
ちなみに、公式フォーラムのBoseカスタマーサポートっぽい人のレスではファクトリーリセット(正確にはプロダクトリセット)を実施するように書かれているため、手順通りに実行したが直らなかった。
Windows
- (既にBose Updaterを起動してしまっている場合は)タスクバーから起動中のBose Updaterを見つけ、右クリック→Exitで終了する
- BOSEUPDATER.EXEをここからダウンロードする
- ダウンロードしたEXEファイルを
C:\Program Files (x86)\Bose Updaterに配置(置換)する - 配置したEXEを実行する(警告が表示される場合は許可する)
- NC700をPCに接続し、https://btu.bose.comにアクセスする
- 以下の画面に変わるまで待機する
 (手順実施後に撮影したため、既にバージョンが下がっている)
(手順実施後に撮影したため、既にバージョンが下がっている) - 画面が上記になったら、
adv↑(上矢印キー)↓(下矢印キー)を順番に押す - 下記画面に切り替わる
 (手順実施後に撮影したため(略))
(手順実施後に撮影したため(略)) - ファームウェアのバージョンを選択し(今回は1.3.1を選んだ)、
Update Nowをクリックする - アップデート処理が完了するまで待機する
macOS
- Bose Updaterを既にインストールしている場合は削除する
- Bose Updater appをここからダウンロードする
- ダウンロードしたBose Updater appを
Applicationsフォルダに配置する - ターミナルを開き、
xattr -cr /Applications/"Bose Updater.app"を入力、実行する
以下Windowsの5以下と同じ手順を実施する。
所感
Boseのヘッドホン/イヤホンはNC 700の前にQuietControl 30を使用していました。

Bose SoundSport wireless headphones ワイヤレスイヤホン ブラック
- 発売日: 2016/06/24
- メディア: エレクトロニクス
ハードウェアとしての品質はどちらも満足いくものです。
ただ、以前からソフトウェアが劣悪・貧弱すぎる点が気になっていましたが、まさかソニータイマーならぬBose遠隔地雷のようなもので(悪意はないにしても)製品が起動しなくなるとは思いませんでした。
個人的には、ソフトウェアにバグが出てしまうのはしょうがないですし、最悪今回のように製品自体が起動しなくなってしまうというのもギリギリ許容できます。
ただそういった問題が発生した場合のレジリエンシーとでも表現したらいいのか、以前のバージョンにロールバックする術が公式から提供されていないのはとても不満です。
フォーラム等でエンドユーザーと接するカスタマーサポートと、恐らくバグを把握しているであろう製品開発チームとの連携が皆無に見える点も気になります。
今回のケースと似た問題に関する質問は公式フォーラム上のスレッドでも散見されましたが、リプライしている公式のカスタマーサポートの手順が役立っていることはほとんどないにも関わらず、馬鹿の一つ覚えのように同じトラブルシュート手順を紹介しており、ユーザーエクスペリエンスを損なう一因になっていると感じます。
製品の利用という最低限の品質に問題をもたらすバグや問い合わせには迅速に応答する必要があると思います。
なんせ無線ヘッドホンの中ではかなり"プレミアム"な価格ですから、購入者はこんな糞みたいな問題に巻き込まれて、サポートセンターに機器の送付、その間の製品利用の中断といった体験はしたくないわけです。
昨今のコロナ禍の中、迅速なカスタマーサポートが難しいのは分かりますし、バグの修正も計画通りに進めることが困難となっていることもある程度察することはできます。
ただ本を正せば、今回の問題はBoseがソフトウェアの重要性を軽視しているところに端を発していると思います。
他の競合からはだいぶ出遅れている完全ワイヤレスイヤホンも、Boseの新作を楽しみに待っていましたが、このようなユーザー体験を与えられるくらいなら購入を控えるかもしれません。
今後の改善に期待します。
参考
Ubuntu 20.04 LTS (Focal Fossa)のインストール用メディアを作成する
タイトルの通り、最近リリースされたUbuntu 20.04 LTSのインストールメディアをUSBで作成する。
環境
- Windows 10 Pro
- USBメモリ 32GB
手順
公式に記載されている通りの手順に従って作成していく。
はじめに、公式のページからUbuntu 20.04 LTSのイメージをダウンロードする。
今回はデスクトップ版を使用するので、Desktop imageの方をダウンロードした。
インストールメディアにするUSBメモリをWindowsマシンに接続し、マウントされているドライブを確認する。
(私の環境ではE:にマウントされていた。)

Win32DiskImagerをインストールし、起動する。
Image FileはダウンロードしたUbuntuのイメージを、DeviceはインストールメディアにするUSBメモリがマウントされているドライブを選択する。

選択後、Writeをクリックする。
処理が終わればインストールメディアの完成。